Doctor Who ve spárech text miningu
Digital Humanities podruhé
Výlety do fascinujícího světa Digital Humanities pokračují — od grafů jsme se přesunuli k textům. Tak například — jak byste charakterizovali svou oblíbenou knihu v deseti větách? Ve Slate si tuto otázku nedávno položili:
Nothing happened. Harry looked around. Harry said nothing.
Protože jsme však nedávno oslavili 50. výročí zachraňování Země, vesmíru a tak vůbec, jako zdrojový materiál jsem použil seriál Doctor Who, konkrétně jeho poslední reinkarnaci, rokem 2005 počínaje.
Koneckonců, i Doktor má co říct o nových médiích.
Zpátky do taRdis!
K velké nelibosti mých spolužáků jsme se opět vrátili k jazyku „R“. Jejich odporu se nedivím; na první pohled R vypadá jako jednoduchý jazyk, uvnitř je však větší… množství problémů, než bych čekal. Vezměte si už jen ten název: vyhledávače jednopísmenná slova s oblibou ignorují, takže vyhledat konkrétní postupy pro R občas hraničí s šílenstvím. Samotný interpret jazyka R bych pro změnu přihlásil do soutěže o nejneužitečnější chybové hlášky. Když už se ale zadaří, výsledky jsou velké a svítivé. Stačí si vzít pastelku.
Pokud jde o textovou analýzu a text mining obecně, R nabízí velké množství užitečných a vcelku i použitelných nástrojů. Vlastně co do získávání dat, jejich analýzy a vizualizace se R máloco vyrovná. Jenom antigravitace chybí.
Text mining dost pokřiví váš pohled na text. Lidé si myslí, že text je souvislá posloupnost slov a vět, ale z nelineárního, objektivního hlediska je to spíše taková koule, šmrdly mrdly, miš maš věc. Nezajímá nás obsah ani jeho význam. Zajímá nás především kvantita — frekvence slov a jejich kontext. Je jedno, zda jde o Shakespearovy sonety, úřední dokumenty nebo titulky k seriálu.
Na počátku byla slova…
Na vstupu může být jakýkoliv prostý text. V mém případě se jednalo o anglické titulky k Doktorovi Who, od první do sedmé série, které jsem si pomocí jednoduchého skriptu ještě předzpracoval do prostého textu. Mým cílem bylo odstranit časové značky a irelevantní části textu — zvukové popisky a autorství titulků. Šlo by to provést i v R, ale v Ruby jsem si přeci jen o něco jistější.
Vytvořením textového korpusu ze zdrojových textů však zpracování nekončí. Pokud se chceme zaměřit na jednotlivá slova, je nutné exterminovat stopslova (stop words), která by jinak přebila všechno ostatní. Také nás nezajímá interpunkce ani velikost písmen.
Co s výsledným textem ohlodaným na kost? Můžeme si udělat přehled nejčastějších slov — rovnou jako wordcloud!

Wordcloud nejčastějších termínů po odstranění stopslov.
Ty však mají pouze mizivou vypovídací hodnotu — ba co víc, mohou být rovnou zavádějící. Sloupcové grafy jsou sice nudné, leč přehlednější.
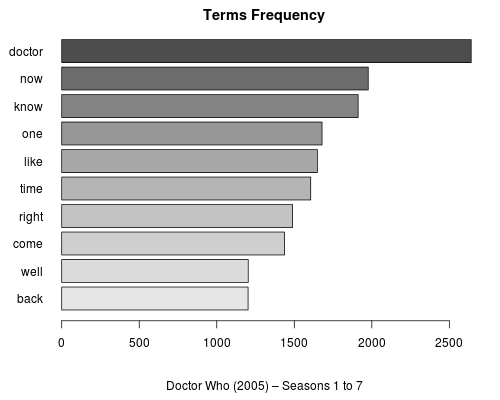
Nejčastější termíny po odstranění stopslov.
Wordcloudy jsou však užitečné jako doplňková ilustrace: „když nevíš co, vraž tam wordcloud, ideálně hezky barevný a vytvarovaný.“

9 z 10 Daleků by wordcloudy exterminovalo. Zbytek vaří soufflé.
A pak n-gramy
Pro zkoumání frekvence výskytu slov dávají mnohem zajímavější výsledky tzv. n-gramy — v tomto případě posloupnost tří slov, tj. trigramy. Je však potřeba si dát pozor na eliminaci stopslov — vzniknou nám zcela nová slovní spojení, která už nereflektují zdrojový text. Takže jaké jsou nejčastější trojslovné fráze ve zkoumaném seriálu?
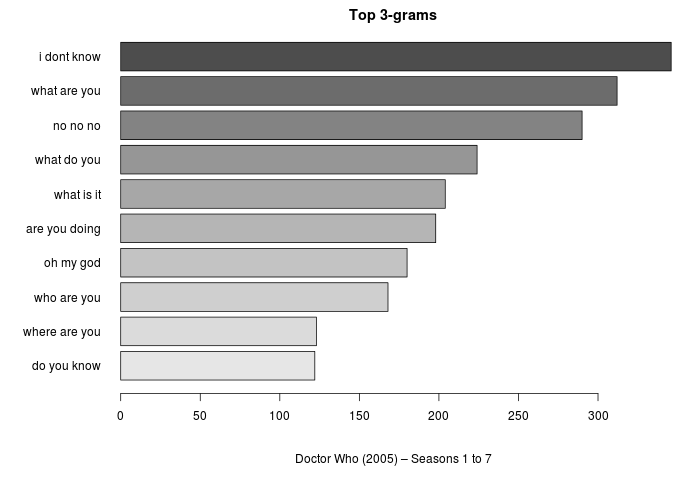
Nejčastější trigramy bez odstranění stopslov.
První tři výsledky mě potěšily a pobavily zároveň. Myslím si však, že mají svou logiku.
I don’t know!
Řada epizod má mysteriózní zápletku, ve které se pracuje s něčím neznámým. Možná i proto na žebříčku dominují začátky tázacích vět. Jeden by však čekal, že za tisíc let už Doktora nic jen tak nezaskočí…
What are you…?
Nejčastější forma otázky je zajímavá i proto, že často padne sama o sobě — jak by se ve sci-fi dalo čekat.
O něco níže v grafu však nalezneme trigram are you doing — to navádí k myšlence, že nejčastější otázka seriálu by mohla být: What are you doing?
A odpověď na ní bude: I don’t know!
No, no, no!
Zde se ukazuje jeden z mnoha nedostatků tohoto postupu: pokud se v textu vyskytne jedno slovo třeba čtyřikrát za sebou (no no no no), výsledný trigram se započítá dvakrát. Čili Doctor Who není až tak negativistický seriál, jak by se mohlo zdát; jen postavy jsou dost hlasité, když se něco kazí.
Dohady jsem si potvrdil ještě tak, že jsem se podíval na 4-gramy:
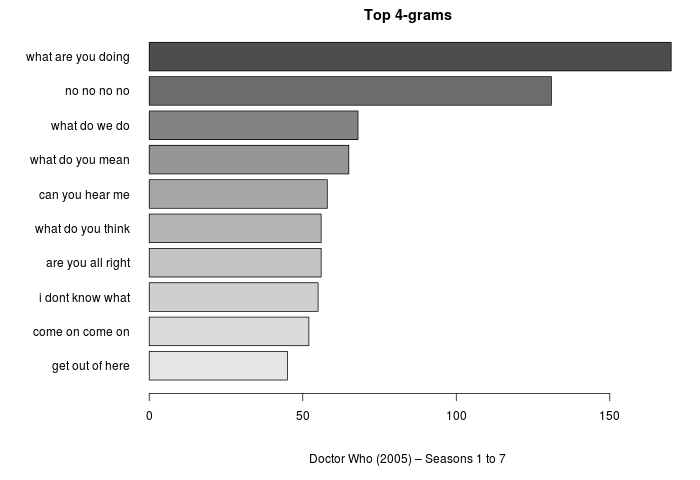
Nejčastější 4-gramy bez odstranění stop slov.
V 5-gramech ještě dominuje no no no no no — zřejmě tušíte, kam to míří. Doctor Who ve čtyřech větách by tedy byl:
- I don’t know!
- What are you doing?
- Oh my god!
- No, no, no, no, no!
K zajímavějším výsledkům by vedla extrakce vět o různé délce slov. Moje pokusy s OpenNLP v tomto směru nedopadly příliš úspěšně; taková analýza mi připadá vhodnější pro knižní texty, kde jsou celistvější věty, než pro dialogy v seriálu.
Relativní dimenze textu
Další oblastí analýzy je porovnávání textů mezi sebou. Zůstaneme-li u frekvence a blízkosti slov, pak dokumenty, ve kterých se opakují stejná slova a stejné fráze, mohou tvořit určitý cluster — ale o tom až někdy příště. Pro ukázku nabízím fylogram ukazující příbuznost textů epizod na základě distanční matice slov.
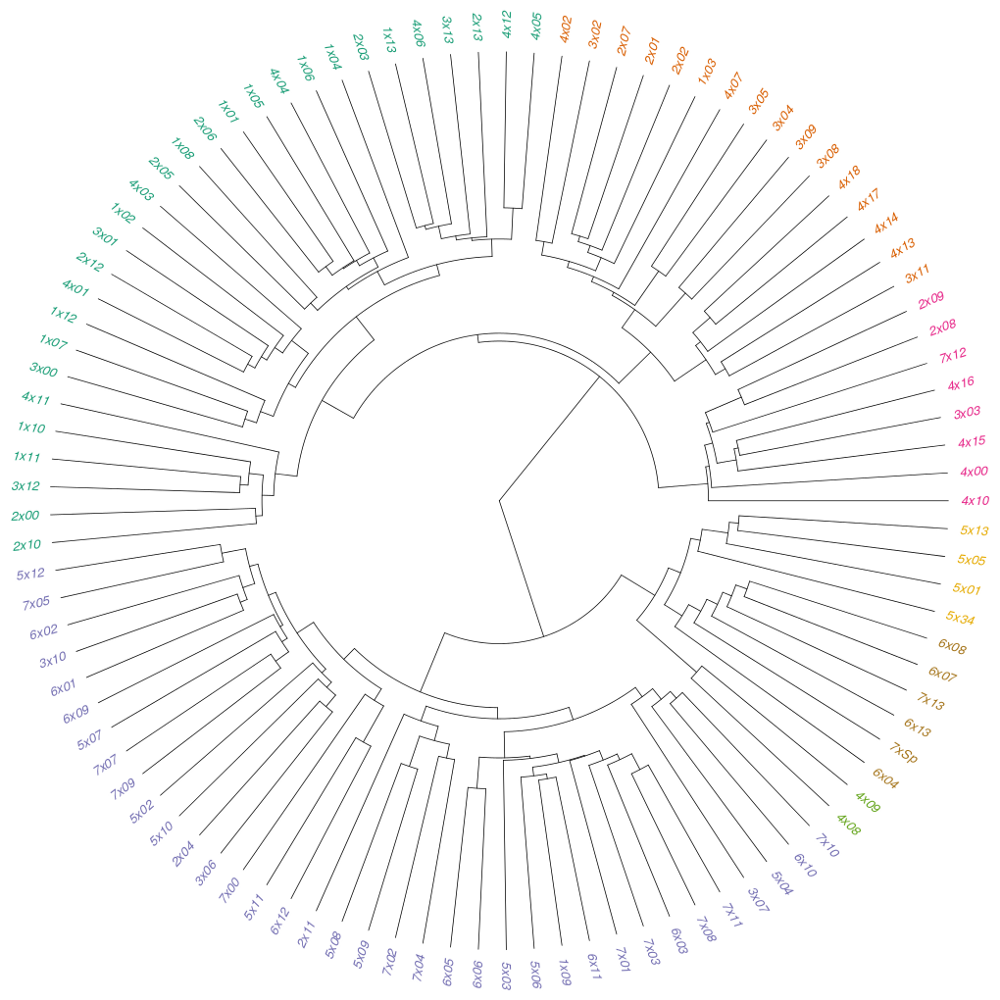
Dvakrát moudrý z toho ale nejsem, bude zapotřebí lépe nastavit váhy a zkusit jiné postupy.
Kompletní zdrojový kód jsem zveřejnil jako Gist.
Od vánočního speciálu nás dělí čtyři adventní neděle. Takže brzy…
